Solve Algorithmic Problems Using Linear Data Structures
~ 12 min read
By Daniel Diaz

/* Let's solve some introductory problems using linear data structures in C++. */
Introduction
In this document we’ll go over linear data structures, their properties and methods, how to implement them using C++ and the Object Oriented Programming (OOP) paradigm.
We’ll also solve 3 interesting problems using the implementations we made for each data structure.
All the following source code will be available in my DS-course github repository.
What is a Linear Data Structure?
A linear data structure (DS from here on) stores data in a linear fashion. Meaning that all its elements or members are arranged sequencially. Each member in a linear data structure is attatched to the next and previous element, so the DS is also contigous.
Common examples of linear data structures are static and dynamic arrays, queues and dequeues, stacks, and linked lists. All of these are considered linear because each element is attatched in an strict order to its neighbours.
As we’ll see in the following section, queues and stacks can be implemented through linked lists.
Implementing Linear Data Structures in C++
We can implement each DS as a class or struct in C++.
Our main class will be the LinkedList, which we’ll use as the base class for the Queue and Stack classes.
Building a Doubly Linked List
We’ll implement a doubly linked list, that is a data structure in which each member
called Node has a reference to other two nodes, the previous and the next node.
Let’s first create our simple Node struct with two main attributes parent, next, and element which is the data we’ll be storing.
It’s also important to implement the node as a template so we’re able to store any data type we want.
template<typename T> struct Node{
T element;
Node *next;
Node *prev;
Node(){
next = prev = nullptr;
}
Node(T el){
Node();
element = el;
}
Node(T el, Node *nxt){
element = el;
next = nxt;
}
Node(T el, Node *nxt, Node *par){
element = el;
next = nxt;
prev = par;
}
};As you can see, each node will have a pointer to the next and previous node. These pointers are initially null.
The linked list will have the following methods. Each of them runs in O(1) time complexity;
push_back(el): Add an element to the back of the listpush_front(el): Add an element to the front of the listpop_back(): Remove an element from the backpop_front(): Remove an element from the frontsize(): Returns the size of the listempty(): Returns true if the list is emptyfront(): Returns the element at the front of the listback(): Returns the element at the back of the list
Now for the fun part, here’s the doubly linked list implementation.
// Made by @DaniDiazTech
#include <iostream>
#include "Node.h"
/// @tparam T
template<typename T> struct LinkedList{
Node<T> *head ;
Node<T> *tail;
int _size;
LinkedList(){
head = tail = nullptr;
_size = 0;
}
int size(){
return _size;
}
bool empty(){
return size() == 0;
}
void push_back(T el){
if (head == nullptr){
push_front(el);
return;
}
Node<T> *newNode = new Node<T>(el, nullptr, tail);
tail ->next = newNode;
tail = newNode;
_size++;
}
void push_front(T el){
Node<T> *newNode = new Node<T>(el, head);
if (head != nullptr){
head->prev = newNode;
}
head = newNode;
if (tail == nullptr){
tail = head;
}
_size++;
}
T pop_front(){
// Cannot pop head
if (head == nullptr){
throw std::out_of_range("Can't pop front of LinkedList");
}
// Access by reference
T &to_return = head->element;
head = head->next;
if (head != nullptr){
head->prev = nullptr;
}
else{
tail = nullptr;
}
_size--;
return to_return;
}
T pop_back(){
if (tail == head){
return pop_front();
}
// By reference not copy element over
T &to_return = tail->element;
tail = tail->prev;
tail->next = nullptr;
_size--;
return to_return;
}
T front(){
if (empty()){
throw std::out_of_range("Can't access empty LinkedList");
}
return head->element;
}
T back(){
if (empty()){
throw std::out_of_range("Can't access empty LinkedList");
}
return tail->element;
}
};It’s a pretty lengthy piece of code isn’t it? Let’s try to explain it bit by bit.
headandtailare the pointers to the nodes at the front and back of the list respectively- If the list has one node, that node is always the head.
- If the list is empty we’ll push to the front without regard if
push_frontorpush_backis being called. - We’ll raise an exception if a non-existing node is being called
- Each time we perform
push_back()the new node will becometailwith a linkprevto the previous tail. - Similarly,
push_front()will set the new node toheadwith a linknextto the previous head.
Implementing a Queue and Stack
Once we have the base doubly linked list struct is almost trivial to implement the Queue and Stack data structures.
It’s also interesting to see that we can implement these linear DS with arrays. If you want to see this kind of implementation here’s the one for the Queue using a dynamic circular array, and the Stack.
In fact I explained the stack array implementation some time ago.
We’ll rename the existing methods and protect those that we don’t want to use.
Regarding to the Queue, here’re its methods, which again run in O(1) time complexity.
enqueue(): Adds element to the end of the queue.dequeue(): Removes element from the front of the queue.front(): Returns element of the front of the queue.size(): Return an integer representing the size of the queue.empty(): Returns true if the queue is empty.
#include "../LinkedList/LinkedList.h"
// Queue inherits from LinkedList implementation
// First in first out : FIFO principle
template<typename T> struct Queue: LinkedList<T>{
private:
using LinkedList<T>::push_front;
using LinkedList<T>::push_back;
using LinkedList<T>::pop_front;
using LinkedList<T>::pop_back;
using LinkedList<T>::back;
public:
using LinkedList<T>::size;
using LinkedList<T>::front;
using LinkedList<T>::empty;
Queue(){};
void enqueue(T el){
this->push_back(el);
}
T dequeue(){
return this->pop_front();
}
};
As you can see we protect the methods from the linked list we don’t want to be accessible by the user.
Here’s a plot representing the performance of this Queue, with respect to the circular array Queue, and the
C++ queue defined in the standard library.
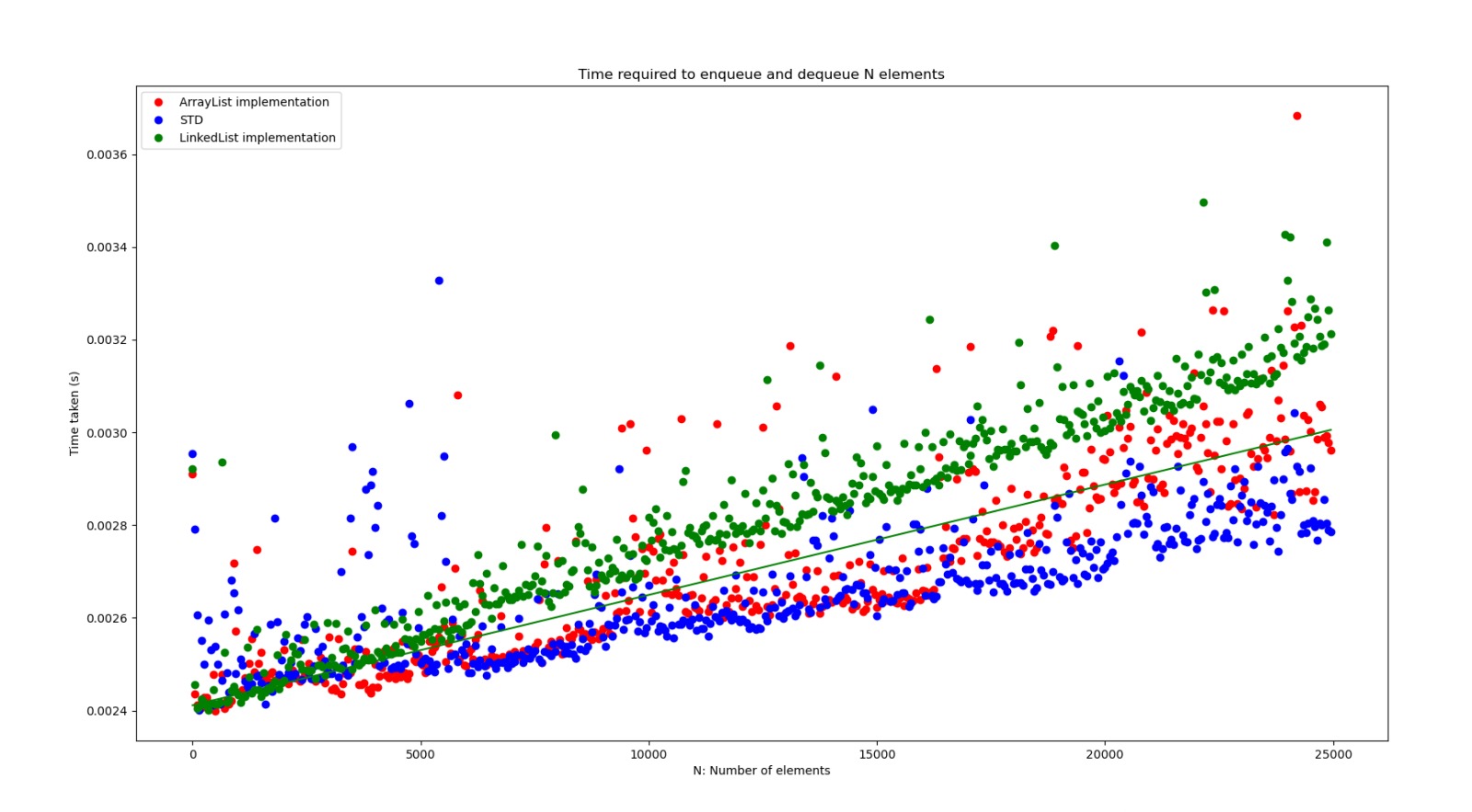
As you can observe, all these implementations run their methods in constant time. However, the LinkedList queue is
the slowest.
Now for the Stack, here’re the following methods that run in O(1):
top(): Returns the element at the top of the stackpush(): Inserts an element at the top of the stack.pop(): Takes out the element at the top of the stack and returns it.size(): Returns an integer, the number of elements the stack currently stores.empty(): You guessed it! Returns a boolean indicating if the stack is empty or not.
template<typename T> struct Stack : LinkedList<T>{
// Use top part of the linked list
private:
using LinkedList<T>::push_back;
using LinkedList<T>::push_front;
using LinkedList<T>::pop_back;
using LinkedList<T>::pop_front;
public:
using LinkedList<T>::size;
using LinkedList<T>::empty;
Stack(){}
T top(){
return this->front();
}
void push(T el){
this->push_front(el);
}
T pop(){
return this->pop_front();
}
};Let’s analyze the performance of this Stack implementation.
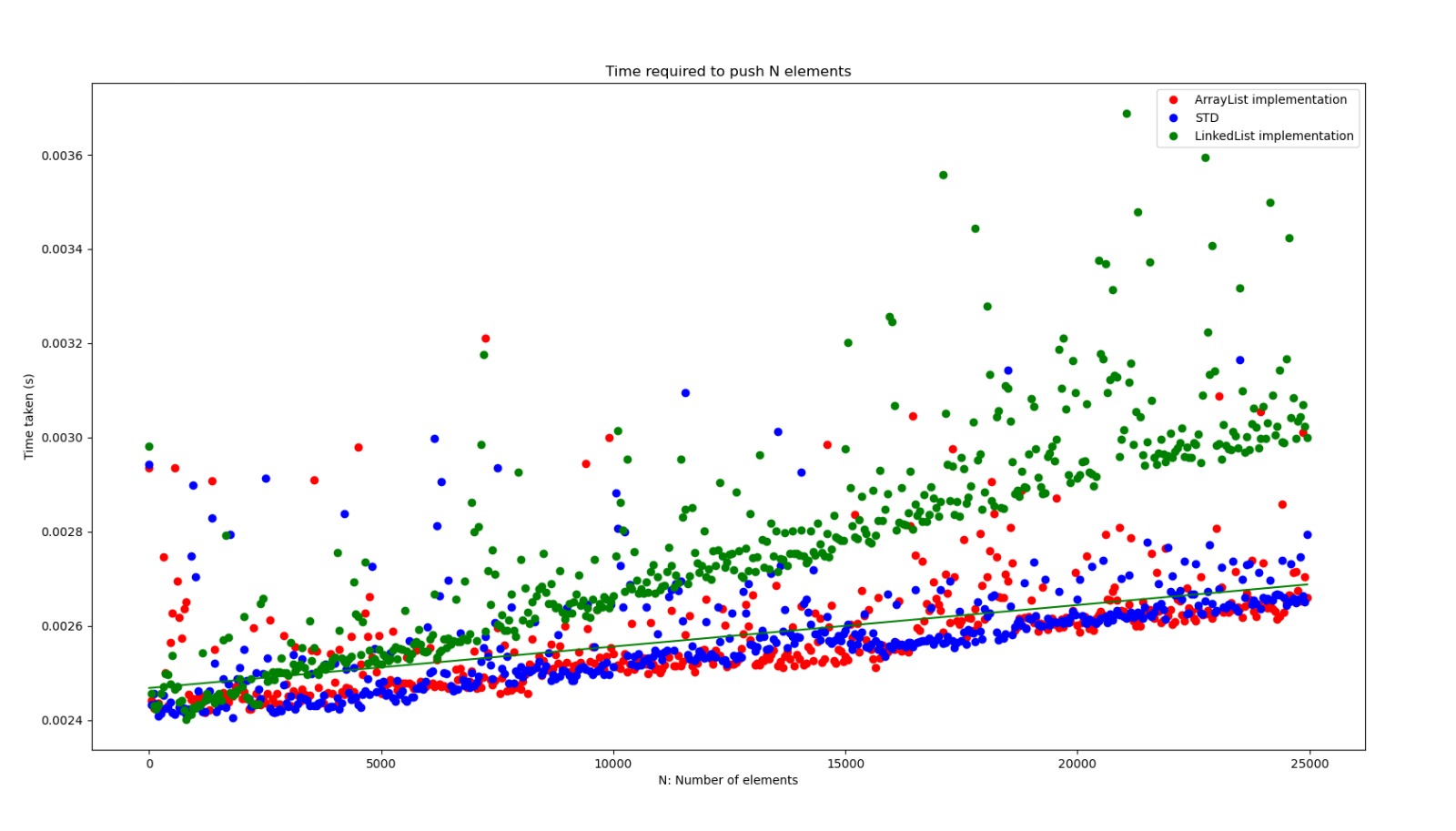
Once again, the linked list implemented Stack comes out as the slowest.
In conclusion, the best option is always to use the data structures available in the standard library, instead of creating our owns DS from scratch.
However, implementing these linear DS is a really good exersice for understanding their internal mechanisms.
Solution to Problems
Why implement a data structure we’re not going to use?
Let’s solve the following problems using the previous implemented data structures.
These problems are part of the problem set of the 2023 Fall data structures course at the National University of Colombia.
Nearest Lower Height
You’re given an array
with n elements. Where
and
. You’re required to answer for each position
the index of the nearest element to the left of i lower than
.
That is, for each i find:
If there is no such j then output 0.
As you can see we need a linear or “semi-linear” algorithm to solve this problem, since a cuadratic solution would yield time limit.
The solution is to use a stack that stores the values before . Then to answer each query, iterate through the stack popping the elements that are less than the current element. Once we find an element lower than our current one, we print it.
This works in because we insert and pop from the stack each element once in the worst case scenario.
Here’s the C++ driver code:
// Made by @DaniDiazTech
// Need to copy and paste DS implementations to send to online judge
#include <iostream>
#include "../DS-implementations/Stack/StackLinkedList.h"
#include "../DS-implementations/Miscellaneous/Pair.h"
// Overall complexity O(n)
// Each element is inserted at most once, and popped once in the stack
int main(){
int n;
std::cin >> n;
// Pair: height, position
Stack<Pair<int, int>> min_stack;
// Insert identity element
min_stack.push(Pair<int,int>(0, 0));
for (int i =1 ; i <= n; i++){
int x; std::cin >> x;
while (min_stack.top().first >= x){
min_stack.pop();
}
std::cout << min_stack.top().second << " ";
min_stack.push(Pair<int, int>(x, i));
}
std::cout << std::endl;
}Notice how we use a virtual element to represent the situation in which there is no index to the left.
Queue of Teams
In this problem you have to process teams, which are arrays of numbers , and a list of commands defined as follows:
- ENQUEUE
x: Insert elementxto its corresponding position. - DEQUEUE: Output the first element in a queue.
- STOP: Stops testcases
The judge assures us there are up to commands to process.
The catch is, each time we enqueue an element we have to insert it to the back of the last member of its team in the queue.
If we try to do the obvious processing with a queue, we would end up inserting an element in the middle of the queue in the worst case scenario, resulting in an overall complexity of .
To avoid the TLE (time limit) veredict, we have to use a better strategy.
We firstly need a way to get the team that any number
belongs to. Because the value of
doesn’t go over a million, we can create an array mp that stores the number of the team of each element passed to us.
Then, we keep an array teams of queues. This array holds a queue for each team, so when we receive the command ENQUEUE x, we get the team of the number
and enqueue
into teams[mp[x]].
Lastly, to keep track of the team we’re dequeuing from, we have another queue cur that keeps the first team that got into the queue at the front.
The overall complexity of this solution is , where is the number of commands.
Here’s the implementation in C++:
// Made by @DaniDiazTech
#include <iostream>
#include <string>
#include "../DS-implementations/Queue/QueueLinkedList.h"
int main(){
int n;
int mx = 1e6 + 10;
// Uses an array as map
int mp[mx];
int scene = 1;
while (std::cin >> n){
if (n == 0) break;
std::cout << "Scenario #" << scene << std::endl;
Queue<int> teams[n];
Queue<int> cur;
for (int i = 0 ; i < n; i++){
int l;
std::cin>> l;
for (int j = 0; j < l; j++){
int x; std::cin >> x;
// membership of the team
mp[x] = i;
}
}
std::string s;
while (std::cin >> s){
if (s[0] == 'S'){
break;
}
if (s[0] == 'E'){
// enqueue
int x; std::cin >>x;
int team = mp[x];
if (teams[team].empty()){
cur.enqueue(team);
}
teams[team].enqueue(x);
}
else{
// dequeue
std::cout << teams[cur.front()].dequeue() << std::endl;
if (teams[cur.front()].empty()){
cur.dequeue();
}
}
}
scene++;
std::cout << std::endl;
}
}Knight Movements
This is a very interesting problem. Given two positions a and b of an 8 by 8 chessboard, we want to know the minimum quantity of knight movements needed to get from a to b.
We could try to do a backtracking solution, with two states, current position, and ending position.
However there is a better solution involving a queue. We can perform a BFS where the starting node is a, and a distance value of 0 (we need a queue of pairs).
Then at each step of the BFS we try each one of the 8 possible knight movements. If the resulting square is a valid one
we insert it into the queue with a distance value of current + 1.
We do this until we reach the position b. The result is be optimal because we’re trying all the reachable chess squares in ascending order of distance.
The time complexity is where is the number of test cases. This because at a maximum we’ll need to process 64 chess squares for each test case, which is just a constant.
The problem would be more difficult if the size of the chessboard also changed.
Here’s the implementation, using our linked list queue.
// Made by @DaniDiazTech
#include <iostream>
#include <string>
#include "../DS-implementations/Queue/QueueLinkedList.h"
#include "../DS-implementations/Miscellaneous/Pair.h"
struct Move{
int row, col;
Move(int r, int c){
row = r;
col =c;
}
Move(){row = 0; col =0;};
bool valid(int r, int c){
int x= r + row;
int y= c + col;
return (x >= 0 && x < 8 && y >= 0 && y < 8);
}
Pair<int, int> move(int r, int c){
if (valid(r, c)){
return Pair<int, int>(r + row, c + col);
}
else{
return Pair<int, int>(-1,-1);
}
}
};
int main(){
int vis[9][9];
Move moves[8];
moves[0] = Move(2, 1);
moves[1] = Move(2, -1);
moves[2] = Move(-2, 1);
moves[3] = Move(-2, -1);
moves[4] = Move(1, 2);
moves[5] = Move(1, -2);
moves[6] = Move(-1, 2);
moves[7] = Move(-1, -2);
std::string start, end;
while (std::cin >> start){
std::cin >> end;
for(int i =0 ;i < 8; i++){
for(int j =0 ;j < 8; j++){
vis[i][j] = 0;
}
}
Pair<int, int> e(end[0] - 'a', (end[1] - '0') - 1);
Pair<int, int> s(start[0] - 'a', (start[1] - '0') - 1);
// coordinate, value
Queue<Pair<Pair<int,int>, int>> q;
q.enqueue({s, 0});
int mn = 1000;
while (!q.empty()){
auto top = q.dequeue();
int x = top.first.first, y = top.first.second, val = top.second;
if (x == e.first && y == e.second){
mn = val;
break;
}
for (int i =0; i < 8; i++){
if (moves[i].valid(x,y)){
Pair<int,int> p = moves[i].move(x,y);
if (!vis[p.first][p.second]){
vis[p.first][p.second] = 1;
q.enqueue({p, val + 1});
}
}
}
}
std::cout << "To get from " << start << " to " << end << " takes " << mn << " knight moves." << std::endl;
}
}Note how we create a custom struct called Move to assist in the processing of new reachable chess squares.
Summary
Wrapping up this document:
- We implemented the doubly linked list. The Queue and Stack data structures inherited from it.
- STD data structures perform better than the ones created by ourselves.
- We solved three problems using linear data structures.
- These data structured helped us to optimize the performance of our algorithm.